
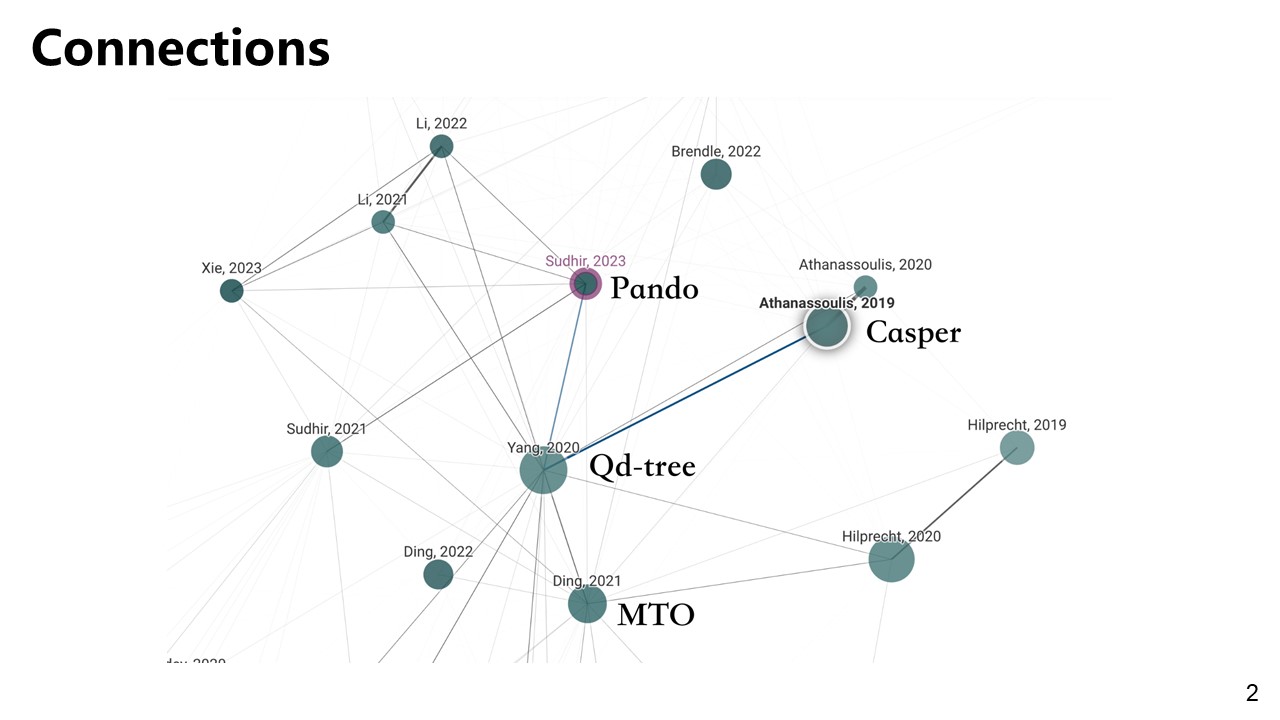
Learned Layouts


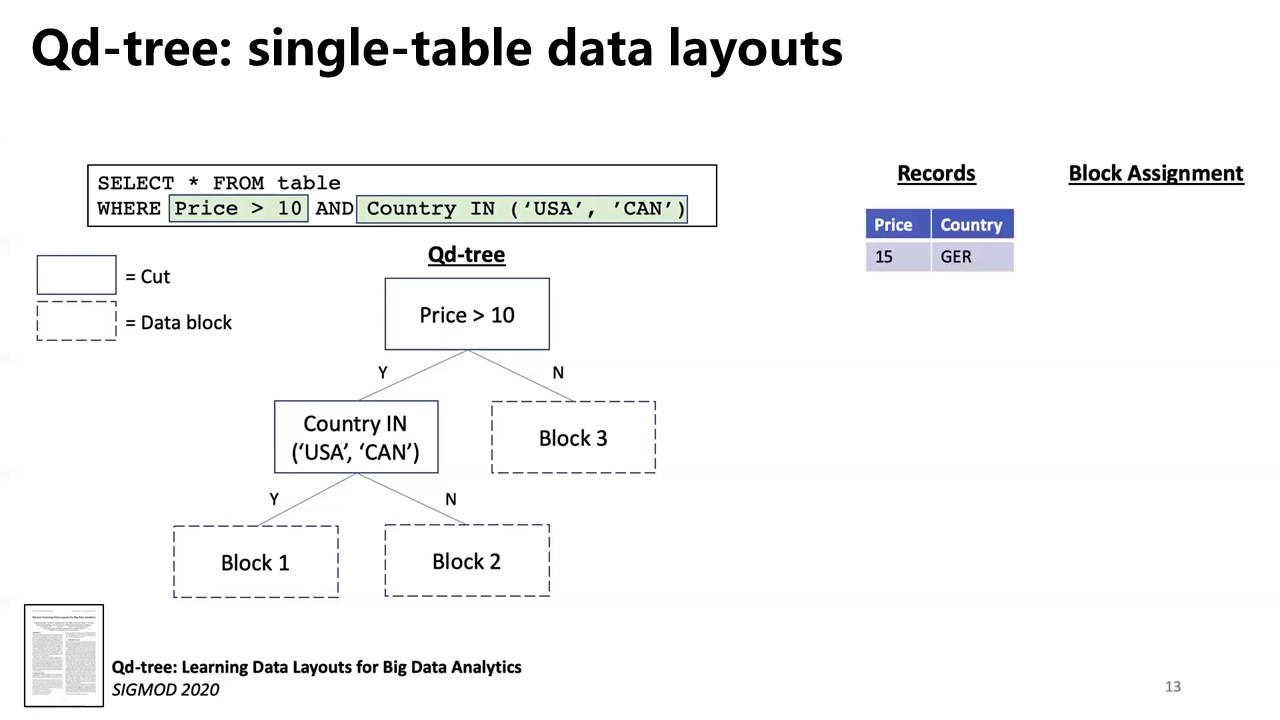
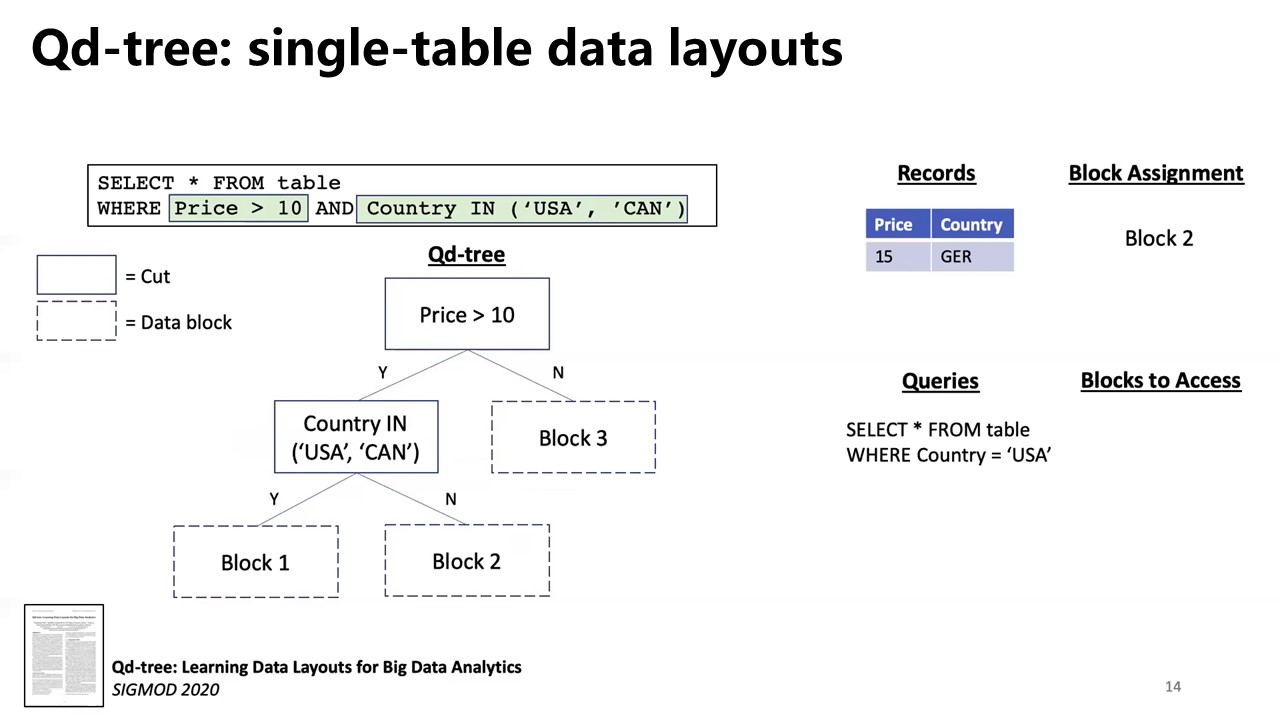
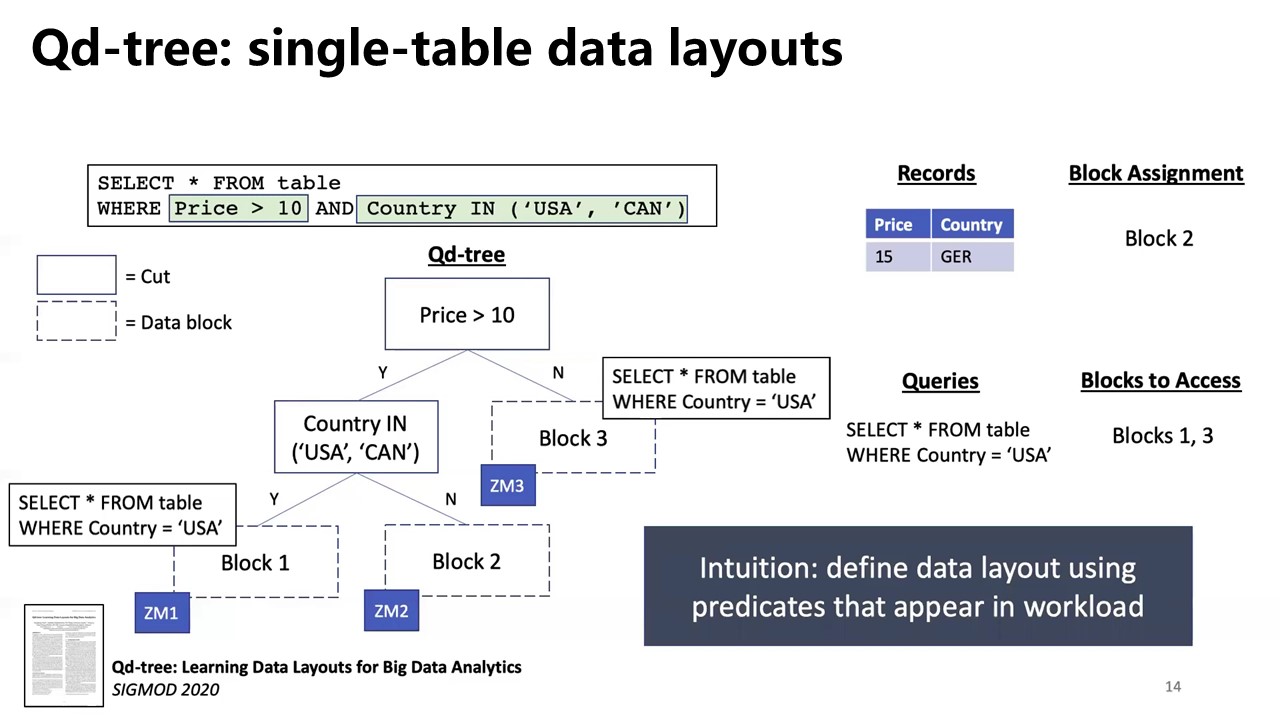
Qd-tree
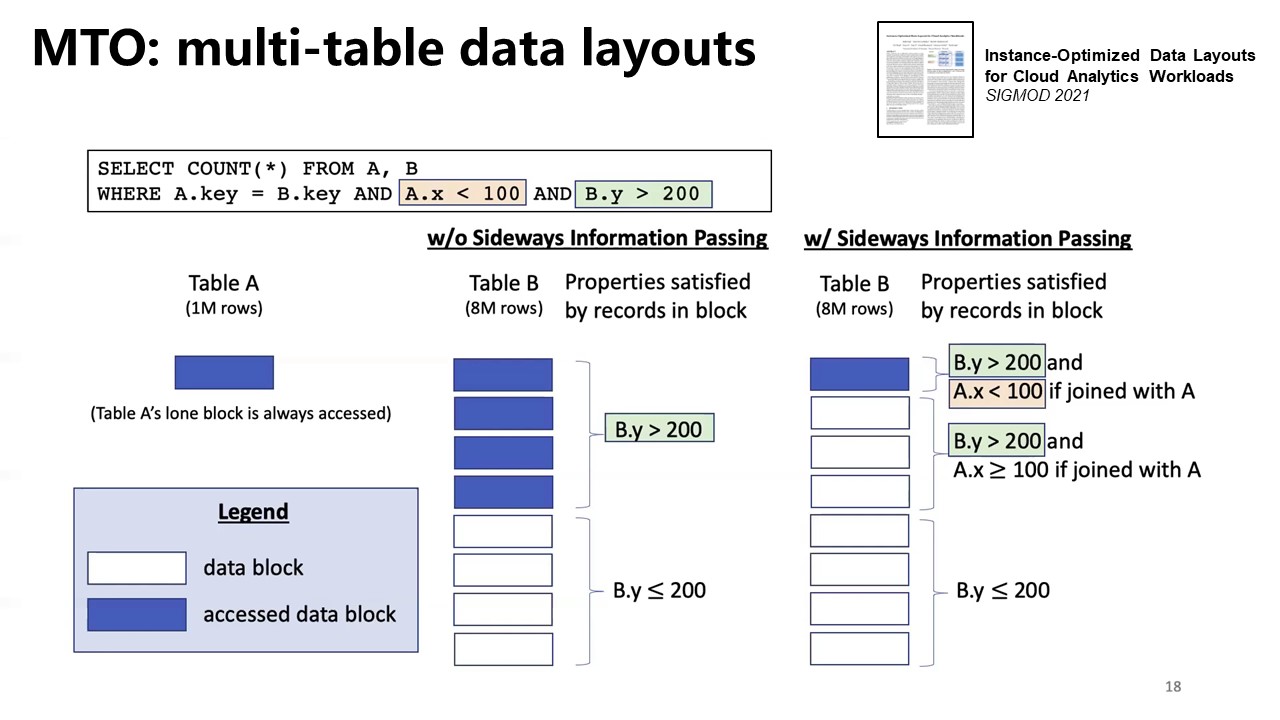
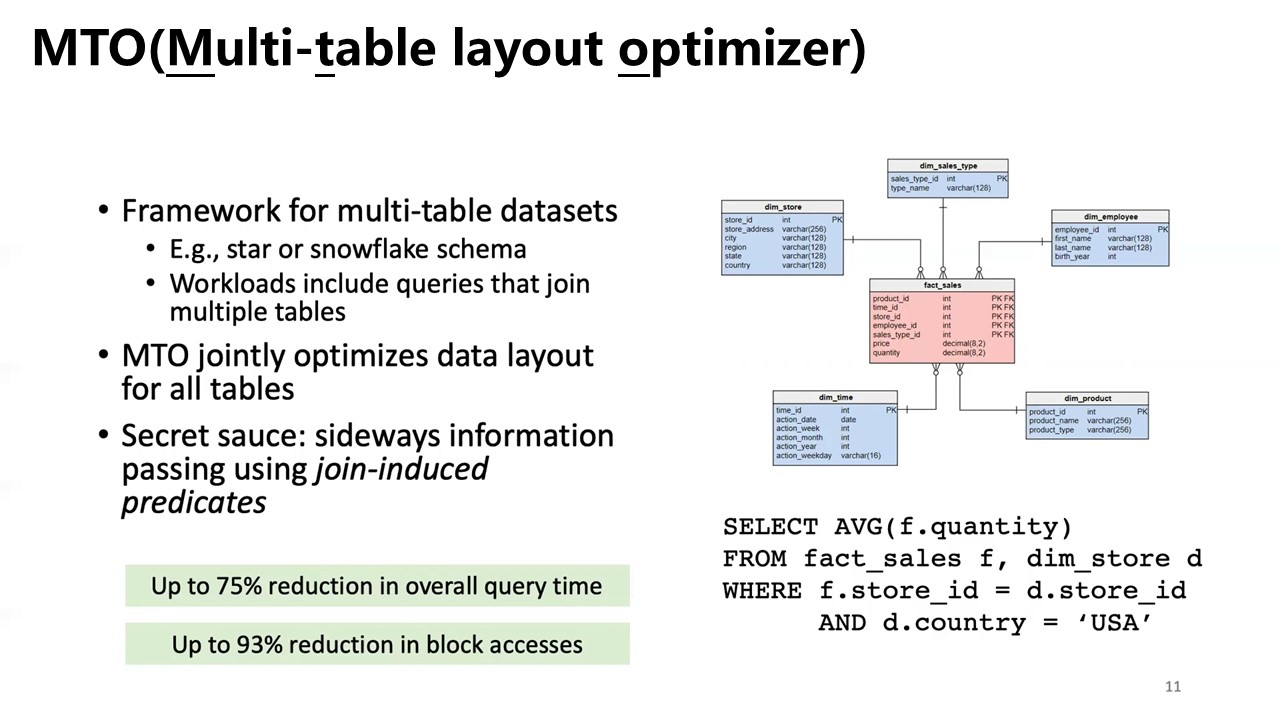
MTO
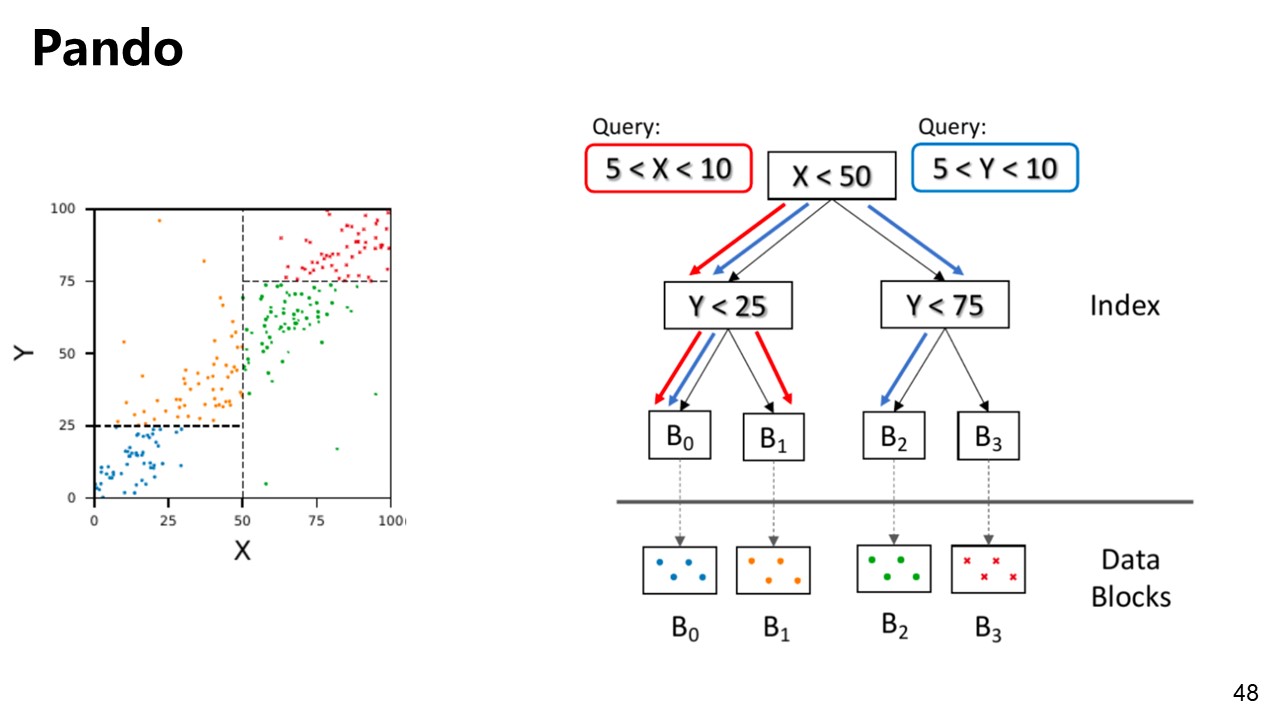
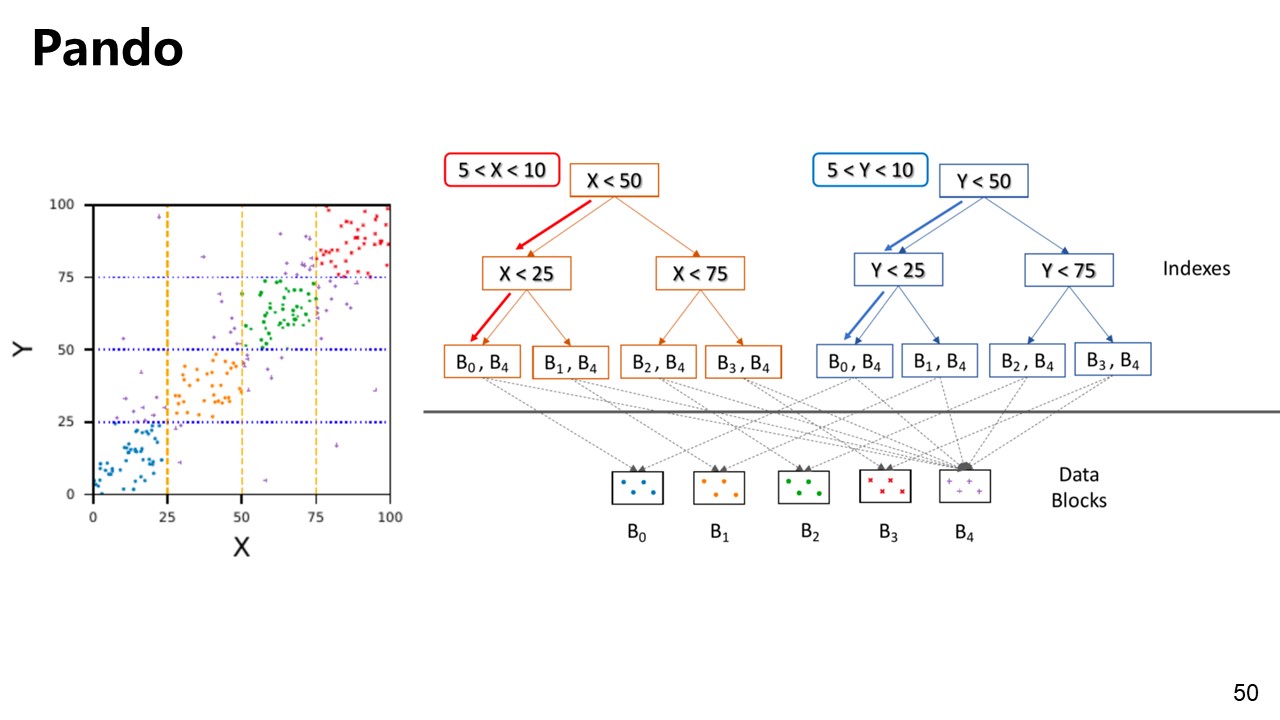
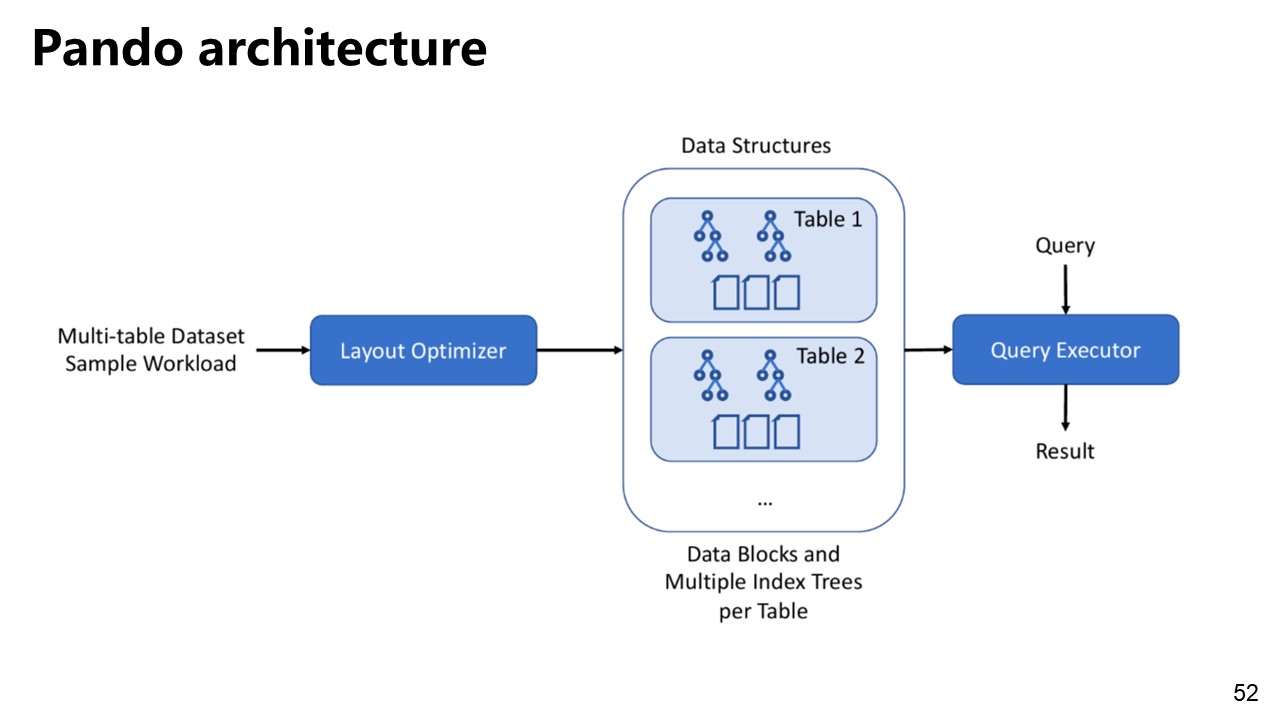
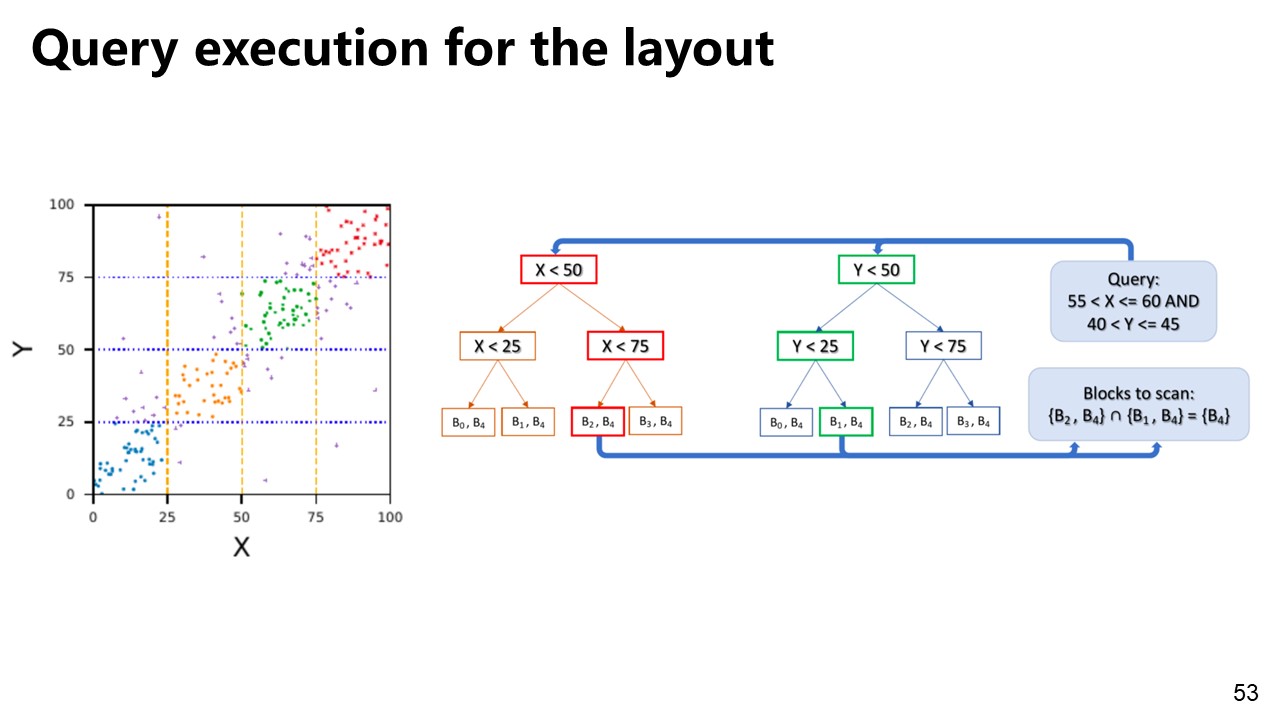
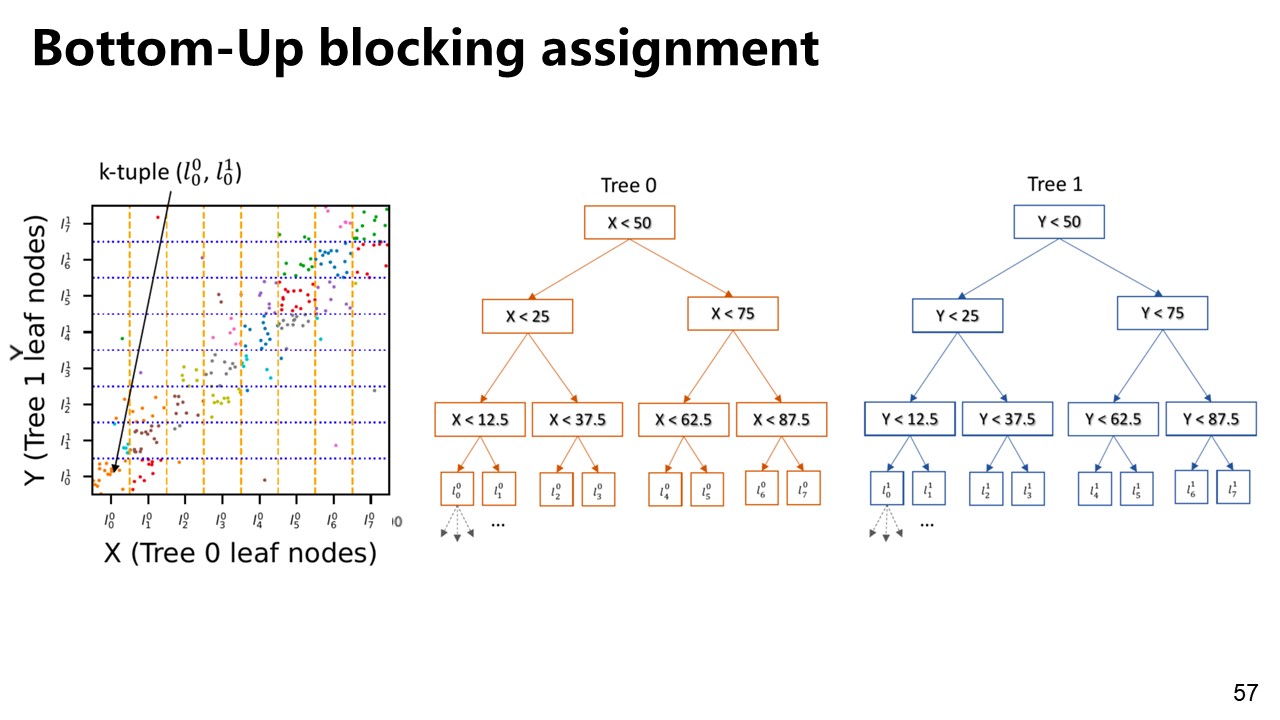
Pando
Results
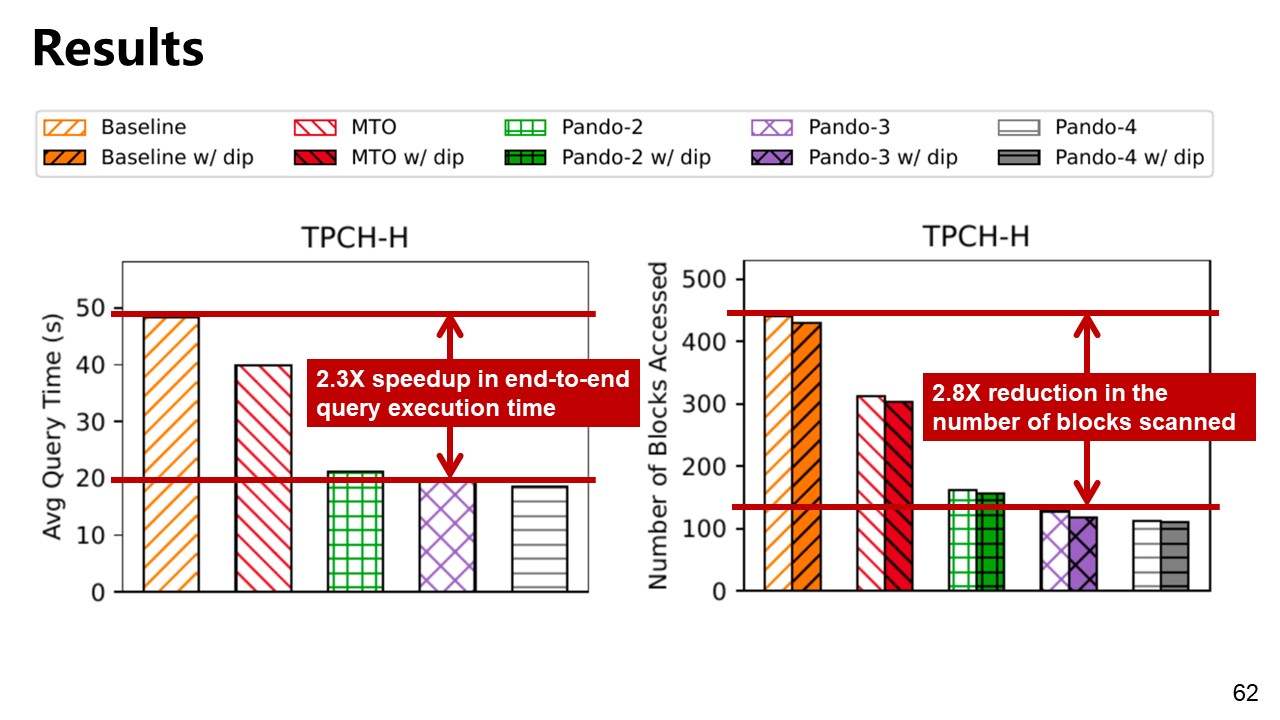
*dip: Data-induced predicates is a concept in the database field that uses data statistics to convert predicates on a table into data-induced predicates suitable for joining tables. Doing this can significantly speed up multi-relational queries because the benefits of predicate pushdown can now be applied to tables other than the table with the predicate.
Summary
Pando: metadata-rich data layout framework.
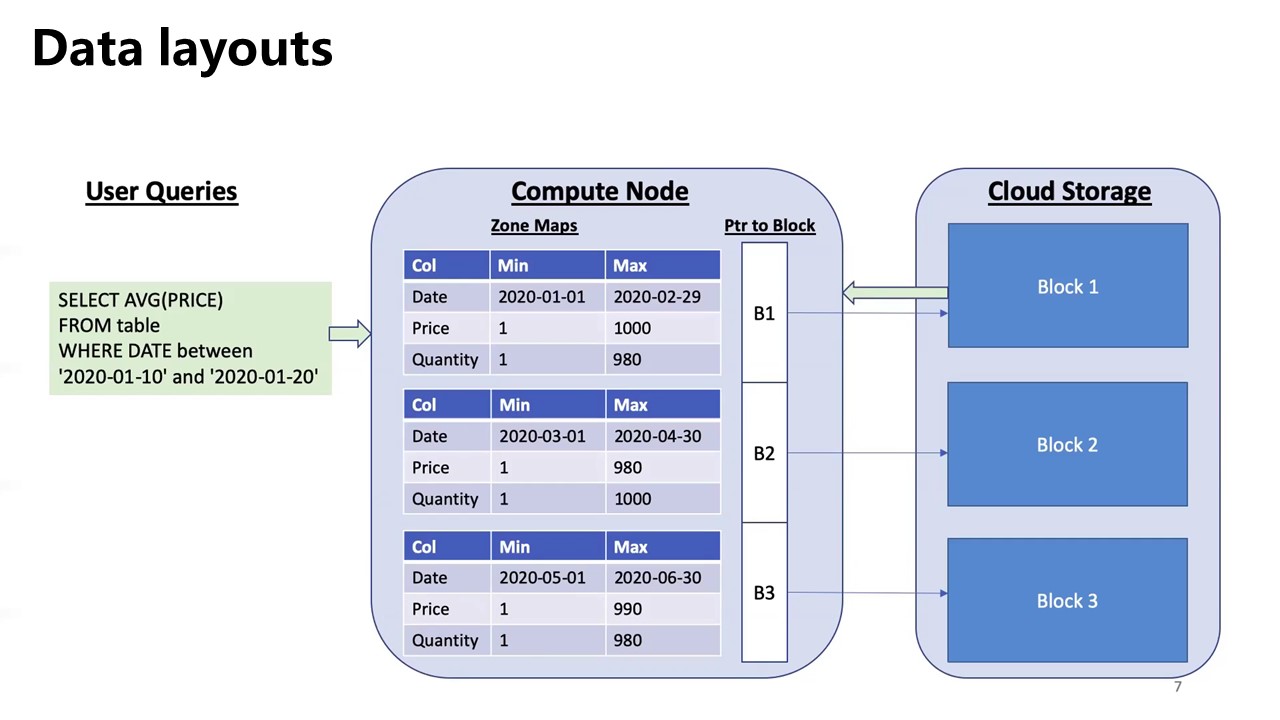
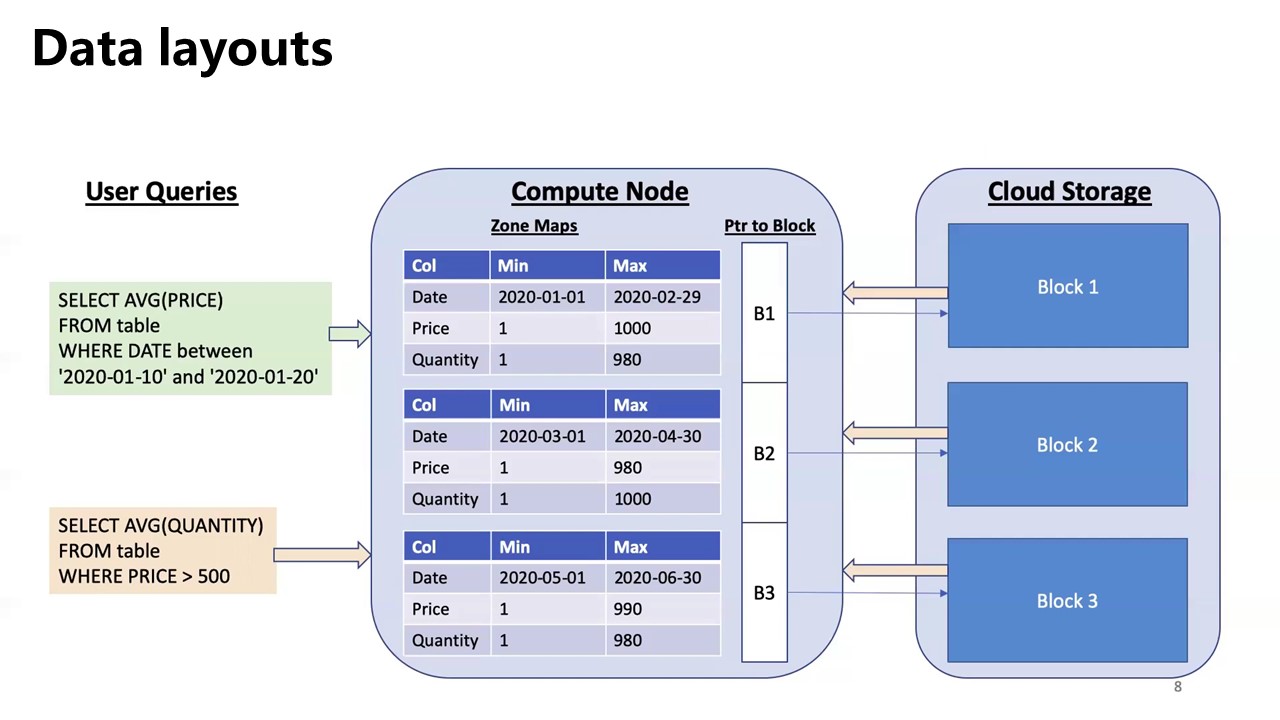
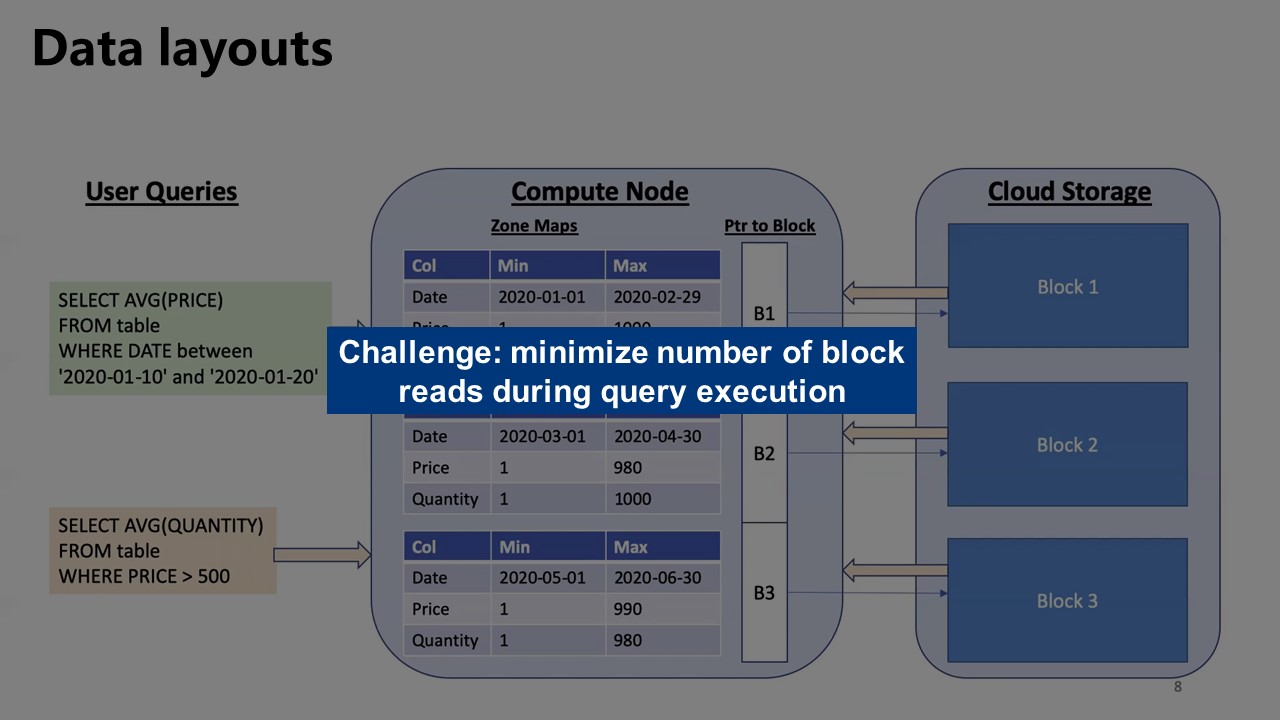
Significant reduction in the amount of I/O performed
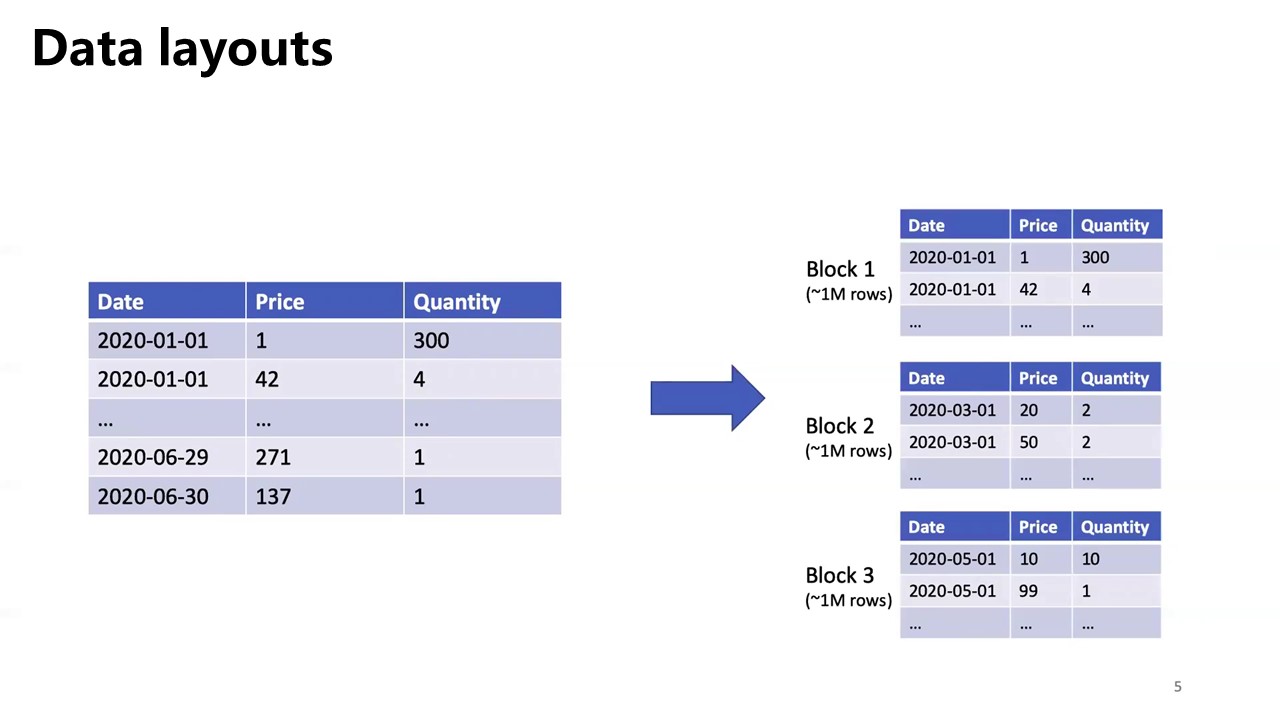
- jointly optimizing the physical layout of the data
- multiple correlation-aware logical partitionings(not covered)
参考
Yang, Z. et al. 2020. Qd-tree: Learning data layouts for big data analytics. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (2020), 193–208. [paper] [video]
[⭐] Ding, J. et al. 2021. Instance-optimized data layouts for cloud analytics workloads. Proceedings of the 2021 International Conference on Management of Data (2021), 418–431. [paper] [video]
Sudhir, S. et al. 2023. Pando: Enhanced Data Skipping with Logical Data Partitioning. Proceedings of the VLDB Endowment. 16, 9 (2023), 2316–2329. [paper]