Brief
The key idea of automatic knob tuning is that, with the help of machine learning techniques, it is reasonable to collect knob tuning data, leverage these data to train a knob tuning model, and utilize the tuning model to recommend knob settings for new similar scenarios, so as to achieve the optimization objectives.
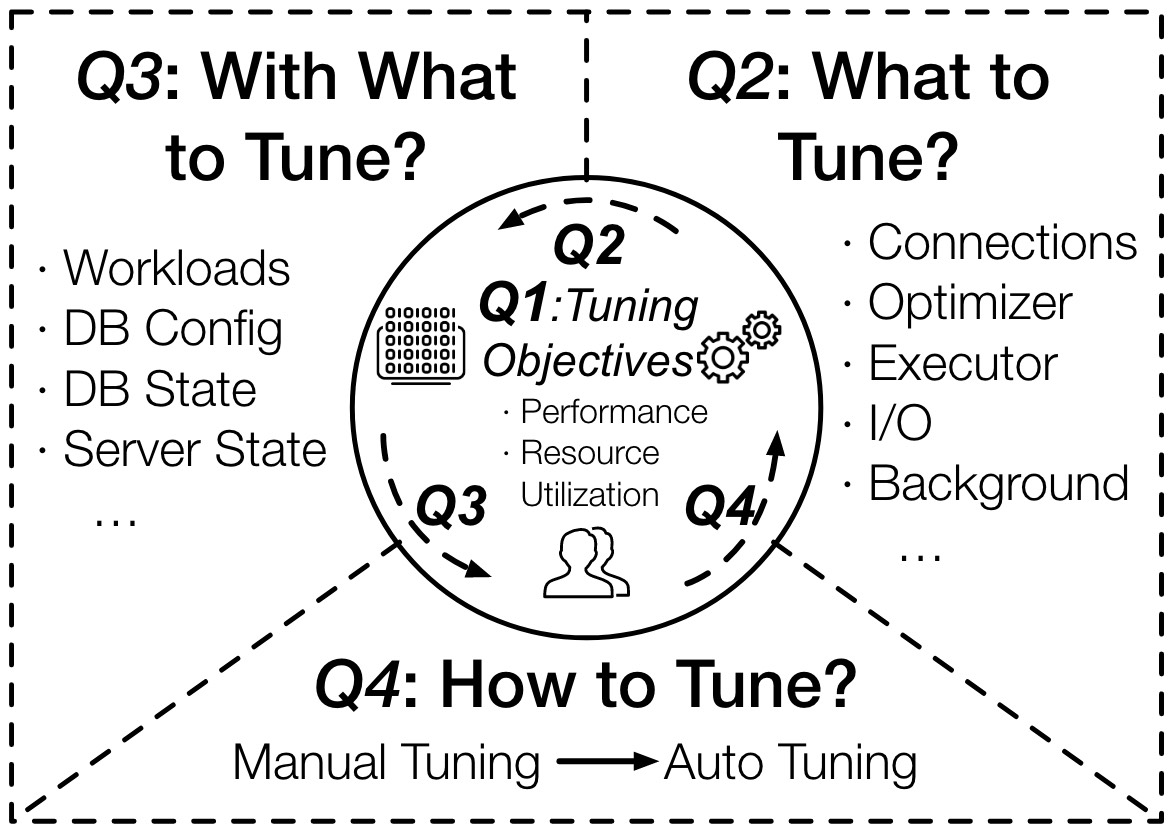
Problems
Tune objectives:
- performance. (1) throughput (2) latency
- improve resource utilization or reduce maintenance costs without sacrificing performance.
Most existing machine learning methods cannot directly provide recommend high-quality knob settings for new tuning tasks and have a long time to train from scratch. Therefore, transfer techniques need to be reviewed.
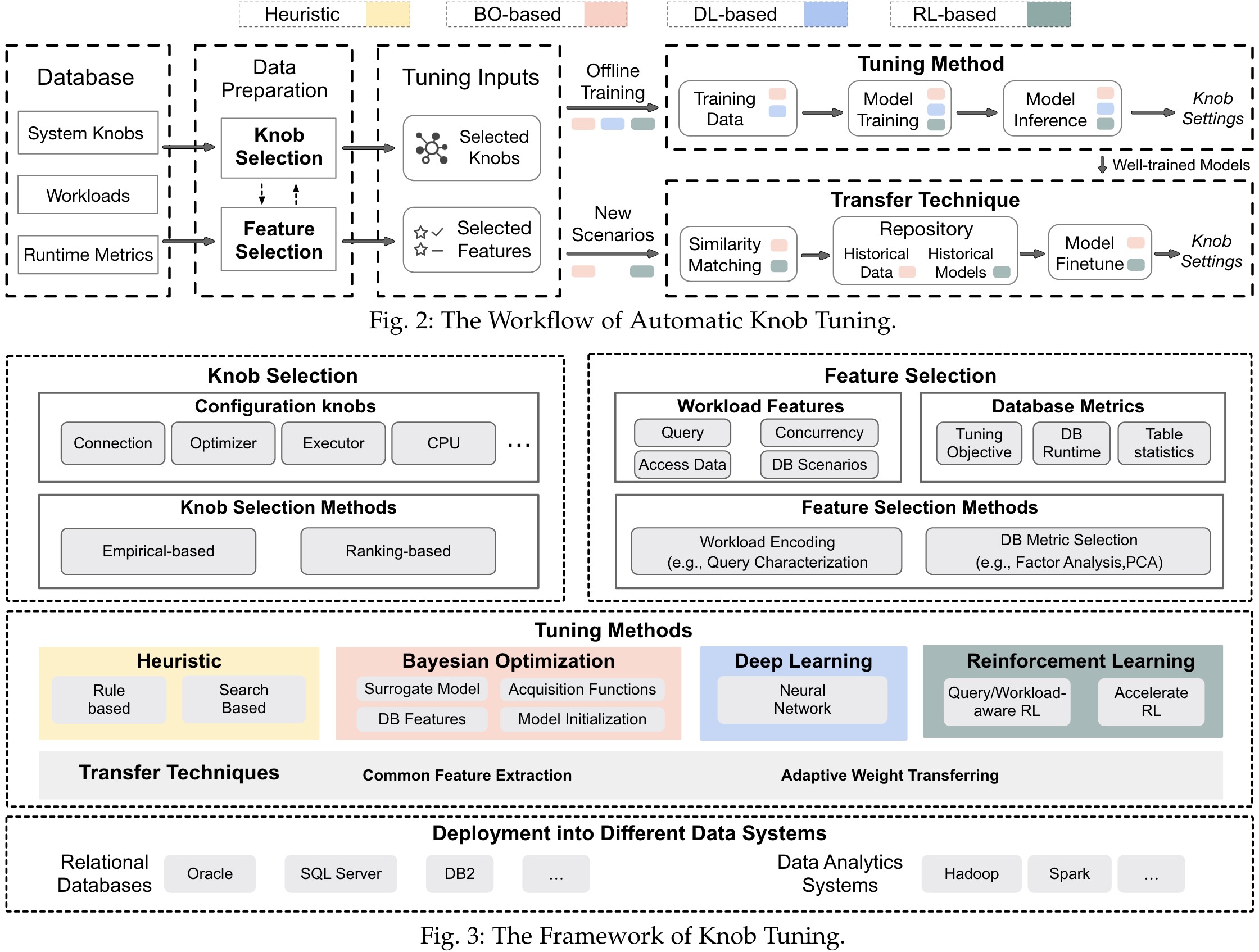
Methods and Challenges
Knob selection includes empirical-based strategies and ranking-based strategies. They rely on some simple assumptions (e.g., assuming the linear relations between knobs and performance). Second, they cannot capture the correlations of knobs. Third, they may miss valuable knobs. Moreover, they rely on a large number of samples to find important knobs and may cause performance regression when the workloads change.
Tuning features are broadly divided into workload features and database metric features. It is vital to design an interpretable feature selection methodology that can automatically select tuning features with reasonable justifications. Besides, apart from historical workloads, there are some techniques that help to predict future workload trends, which can be more useful in tuning the configuration knobs.
As the knob tuning problem is NP-hard, existing tuning methods have four categories, i.e., (i) heuristic methods, (ii) Bayesian optimization-based methods, (iii) deep-learning-based methods, (iv) reinforcement-learning-based methods. Open challenges involves in data distribution aware configuration tuning, incremental configuration tuning and tuning performance prediction.
It is vital to achieve practical learned tuning methods in real scenarios. Thus, transfer techniques are proposed to support dynamic scenarios at different levels. It is challenging to manually select tuning models and adjust the parameters between various ML models. Moreover, it is hard to evaluate whether a learned model is effective in most scenarios, for which a validation model is required.
The paper also discuss how to deploy existing knob tuning techniques for relational databases and big-data systems. In addition, the paper discuss three configuration tuning problems beyond knobs, including index tuning, view tuning, and partition tuning.
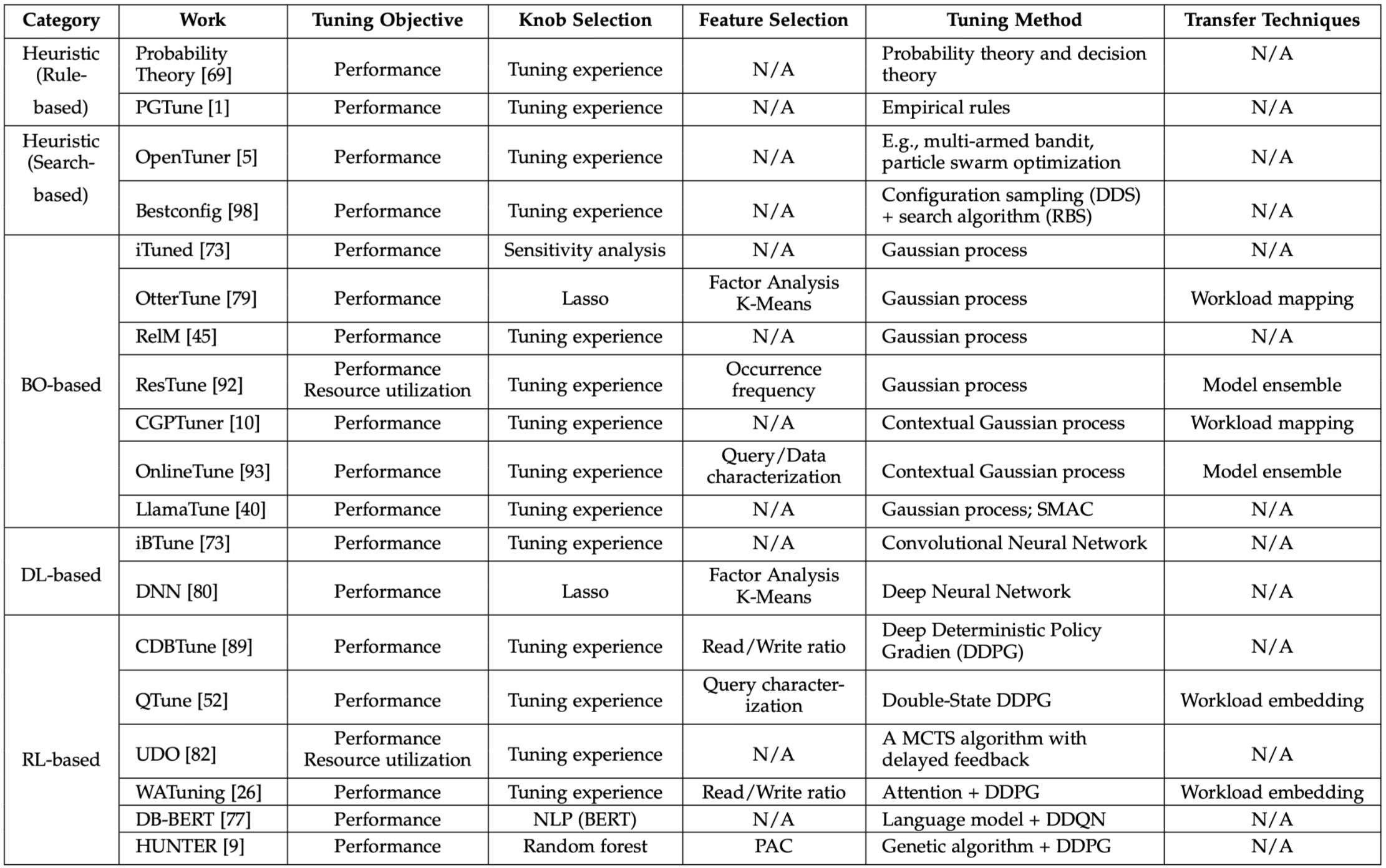

Reference
- X. Zhao, X. Zhou, and G. Li, “Automatic Database Knob Tuning: A Survey,” IEEE Transactions on Knowledge and Data Engineering, 2023, Accessed: Oct. 02, 2023. [paper]