Brief
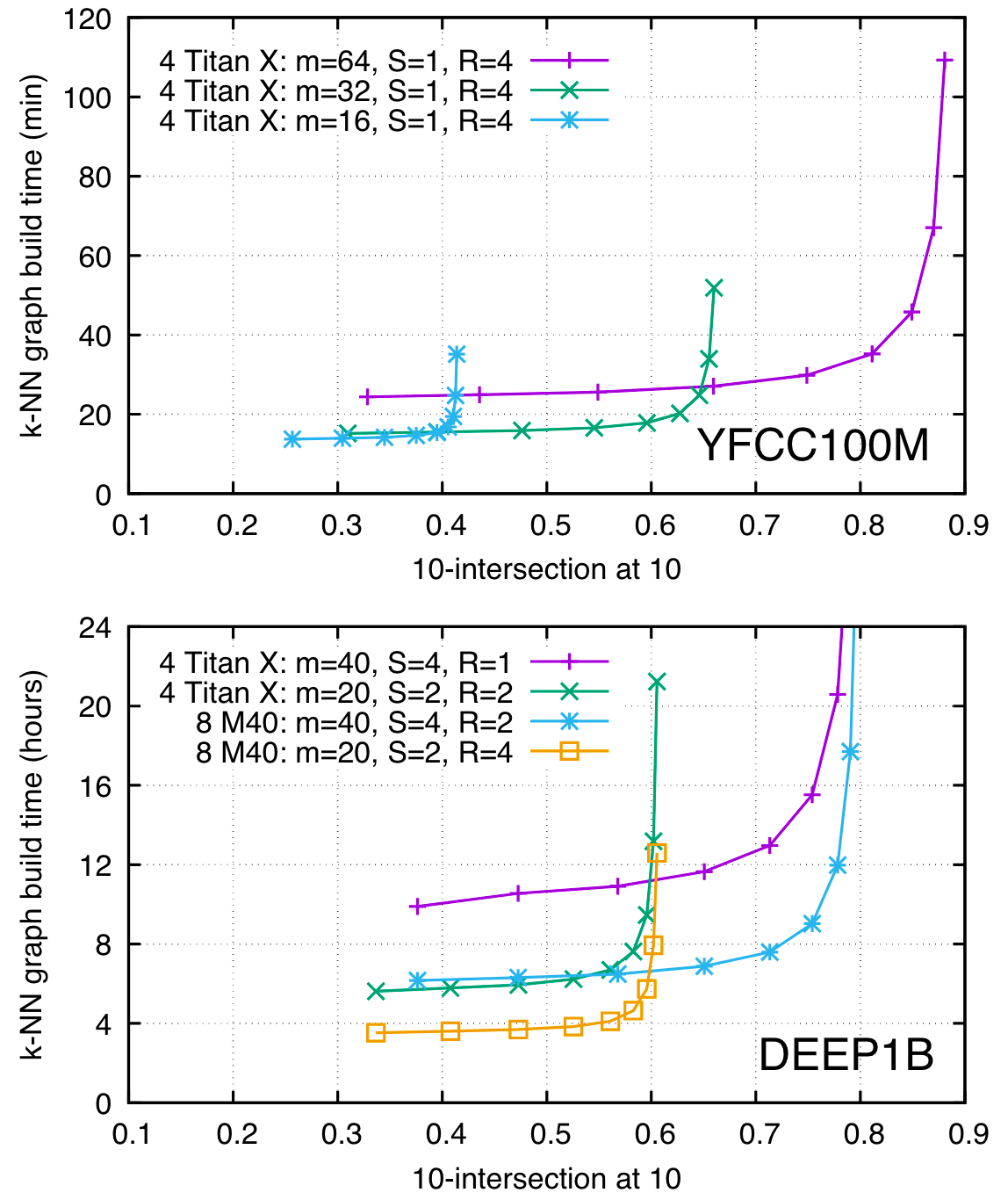
In this paper, Faiss aims to utilize GPUs for similar search find workload by a design of k-selection. It is based on the method of product quantization (PQ) codes, which origin proposal is IVFADC. Therefore, it is able to handle billion-scale datasets or non-exhaustive search. For the YFCC100M dataset, Faiss takes in 35 minutes to construct a high accuracy k-NN graph on 95 million images. Construction of a graph connecting 1 billion vectors in less than 12 hours on 4 Maxwell Titan X GPUs.
This paper makes three main contributions:
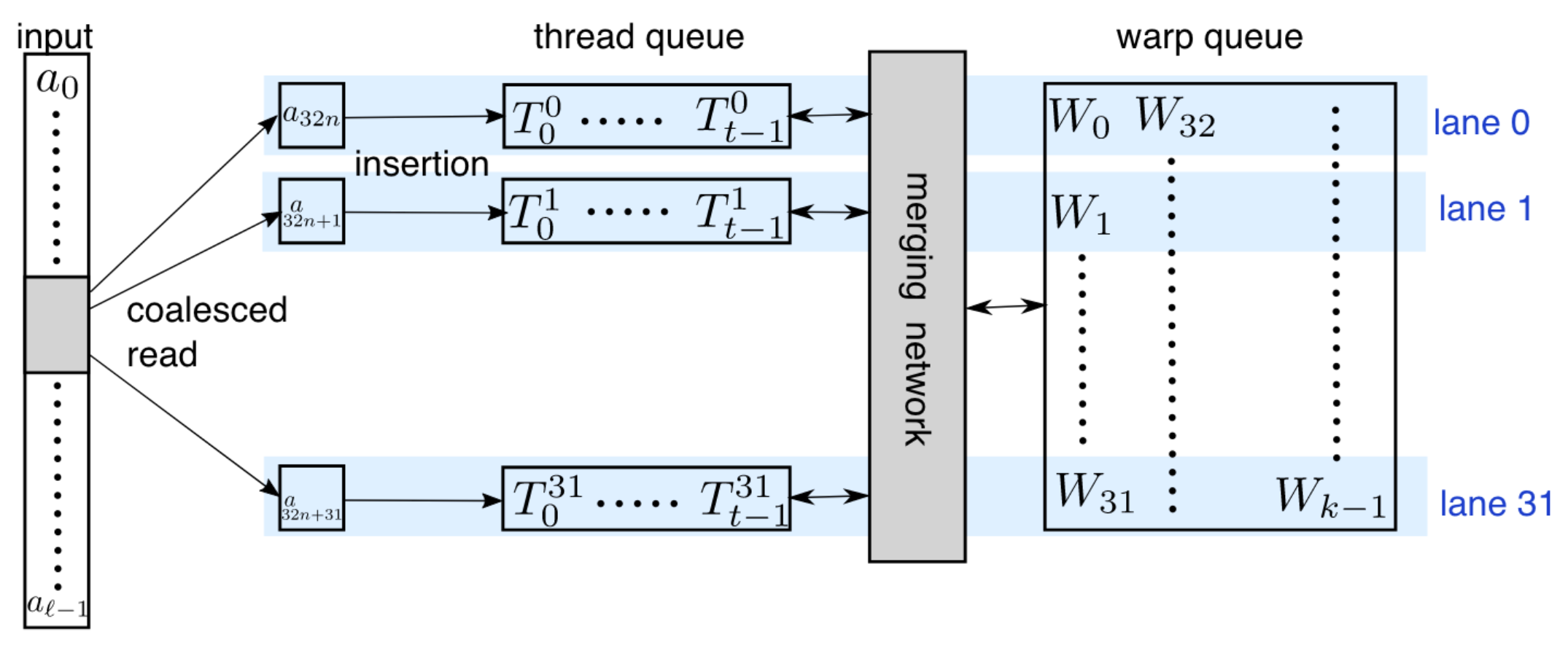
- A GPU k-selection algorithm, operating in fast register memory and flexible enough to be fusable with other kernels, which the paper provide a complexity analysis;
- A near-optimal algorithmic layout for exact and approximate k-nearest neighbor search on GPU;
- A range of experiments that show that these improvements outperform previous art by a large margin on mid- to large-scale nearest-neighbor search tasks, in single or multi-GPU configurations.
Background
Faiss is an open-source clustering and similarity search library developed by Facebook AI, providing efficient similarity search and clustering for dense vectors on RAM-only. It supports searches for billions of vectors and is currently the most mature nearest neighbor search library. It contains multiple algorithms for searching for vector sets of any size for which is determined by RAM memory.
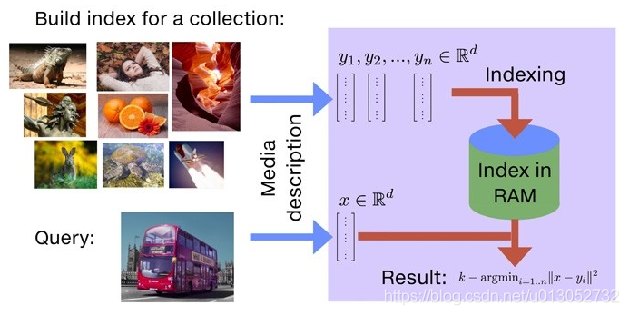
Binary codes and quantization methods are two most popular vector compression categories. Both two search neighbors that does not require reconstructing the vectors.
Reference
- J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019, doi: 10.1109/TBDATA.2019.2921572.