Introduction
For HTAP databases, there are two conflicting goals:
Append new data for fast ingestion.
Organize/sort data for fast querying.
Ideally, a HTAP database should achieve these goals by having dense sorted columns to support scans and selective queries with minimal update cost. However, what is usually a good data layout for an update-heavy workload, is not well-suited for a read-mostly one and vice versa.
Therefore, the paper introduces Casper, a storage engine has workload-aware optimal colum layout, which fixes the problem of using fix method to handle hybrid workloads.
Design Primitives
Normally, there are three kinds of data organizations: append order, sorted and partitioned.
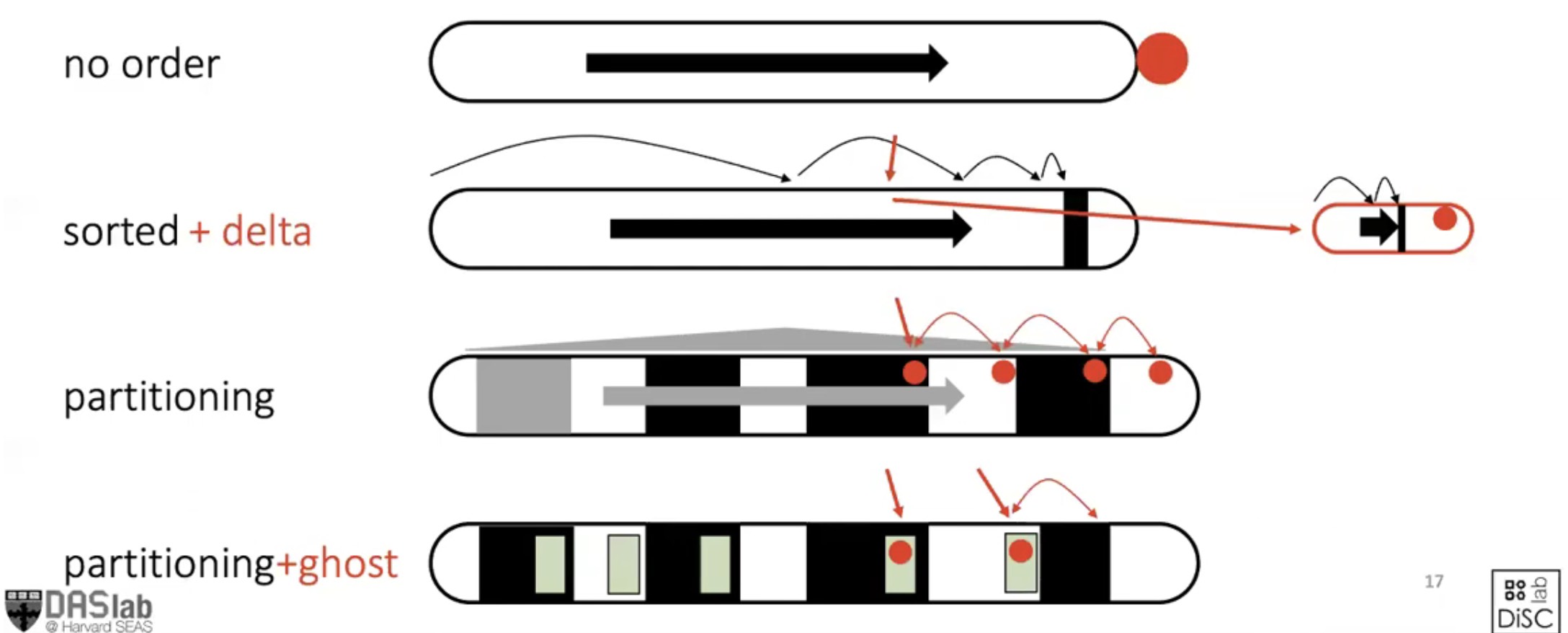
Global data layout decisions miss opportunities for fine-grained optimization. Meanwhile, optimal layout through fine-grained local decisions has massive performance benefits. To achieve this, the system depends on the exact workload. For append order and sorted organization, they apply global decisions. The partitioned allows for different fine-grained local decisions in different parts of the domain. Casper achieve that by using access frequency method.
In Figure 1, no order type is good for scans and for appends. Sorted + delta type is good for selective queries and a few updates. Paper assumes that partitions wih non-overlapping ranges. And each partition internally does not have to be sorted. For partitioning, under normal circumstances, data is tightly packed. The insertion operation first locates the appropriate partition position, then attempts to create a vacant slot within that partition to insert the data. A method known as “Ripple-Insert” is employed for this purpose. To make room for the new data, each partition steals a position from the head of the subsequent adjacent partition. The adjacent partition then continues to seize a position from its subsequent partition, and so on. This process facilitates the overall adjustment of the data, propagating much like ripples in water.
Design
The partitioning of data is fundamentally a division of contiguous blocks. This is achieved by marking whether a block at a certain position is a partition boundary. Thus, the expression and output of partition division involve outputting the binary values corresponding to the indices of the boundary blocks in the form of a bit-vector.
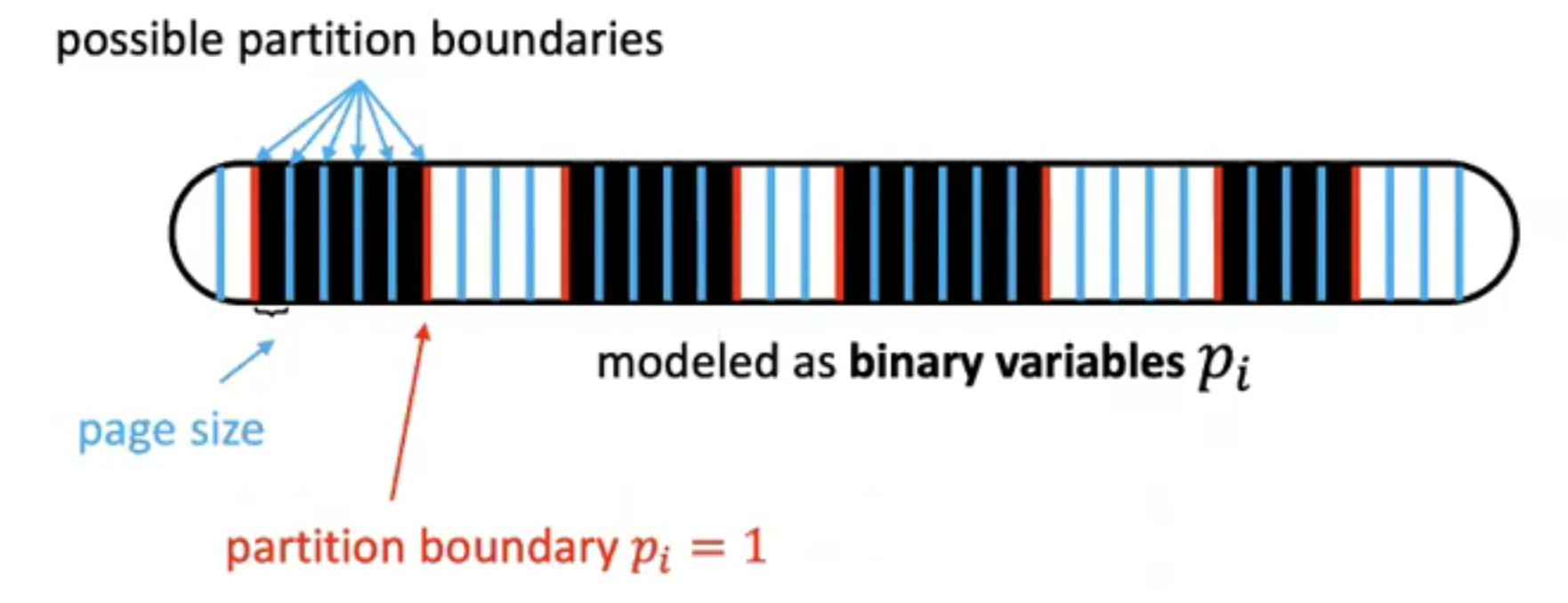

The system maximize performance using run-time workload knowledge.
Evaluation and Conclusion
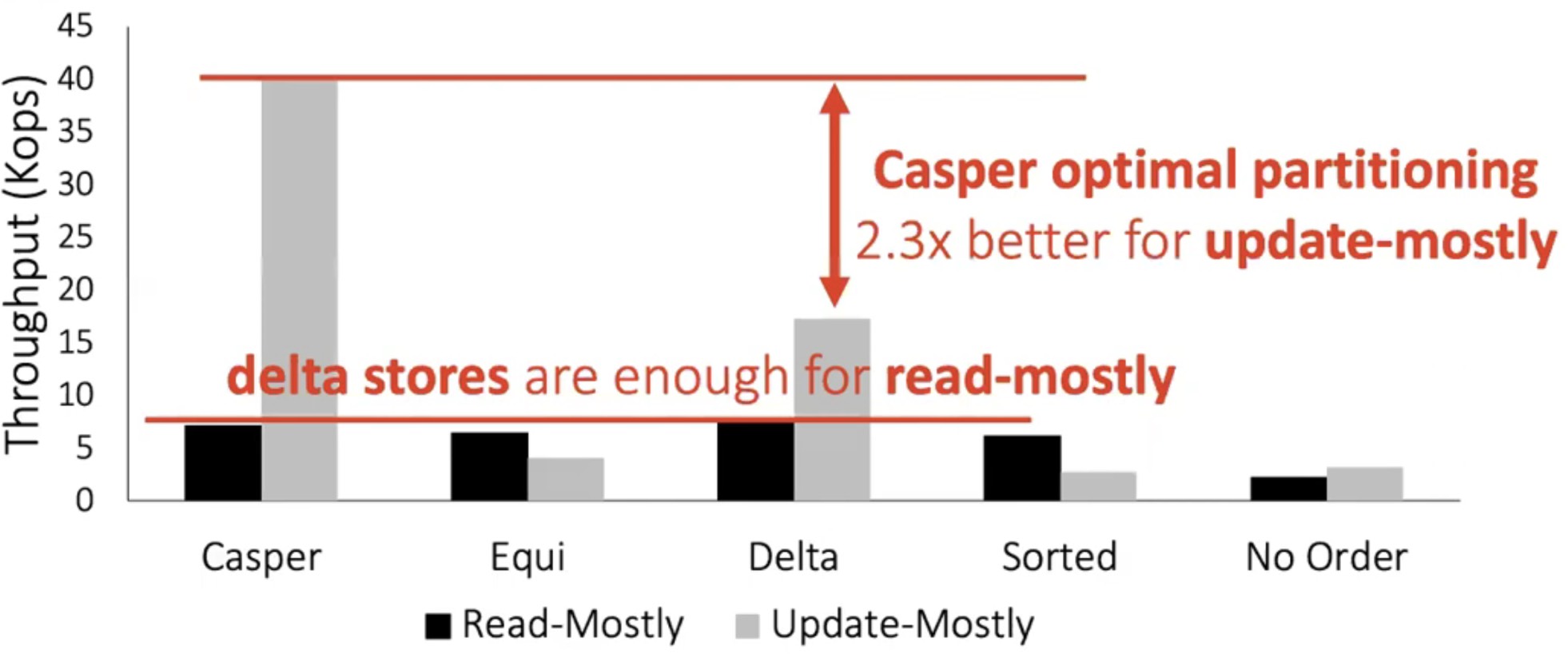
From Figure 4, it can be learned that delta buffers are enough for read-mostly workload. Casper is suitable for update-mostly workload.
Casper, a storage engine has workload-aware optimal colum layout, co-optimize reads and writes through tunable partitioning. It further explores ghost values to insert with minimal data movement. And it offers optimal performance using workload-driven fine-grained decisions.